BigQuery
BigQuery is Google's cloud database service. You can query the database using SQL directly in your browser with:
-
Speed: Even very long queries take only minutes to process.
-
Scale: BigQuery magically scales to hexabytes if needed.
-
Economy: Every user gets 1 TB free per month for querying data.
Ready to start? On this page you'll find:
Getting Started
Before starting: Create your Google Cloud project
To create a Google Cloud project, you just need an email registered with Google. You need to have your own project, even if empty, to make queries in our public datalake.
- Access Google Cloud. If it's your first time, accept the Terms of Service.
- Click on
Create Project. Choose a nice name for the project. - Click on
Create
Why do I need to create a Google Cloud project?
Google provides 1 TB free per month of BigQuery usage for each project you own. A project is necessary to activate Google Cloud services, including BigQuery usage permission. Think of the project as the "account" where Google will track how much processing you've already used. You don't need to add any card or payment method - BigQuery automatically starts in Sandbox mode, which allows you to use its resources without adding a payment method. Read more here.
Accessing the basedosdados datalake
The button below will direct you to our project in Google BigQuery:
Now you need to pin the DB project in your BigQuery, it's quite simple, see:
!!! Warning The Pin a project option may also appear as Star project by name
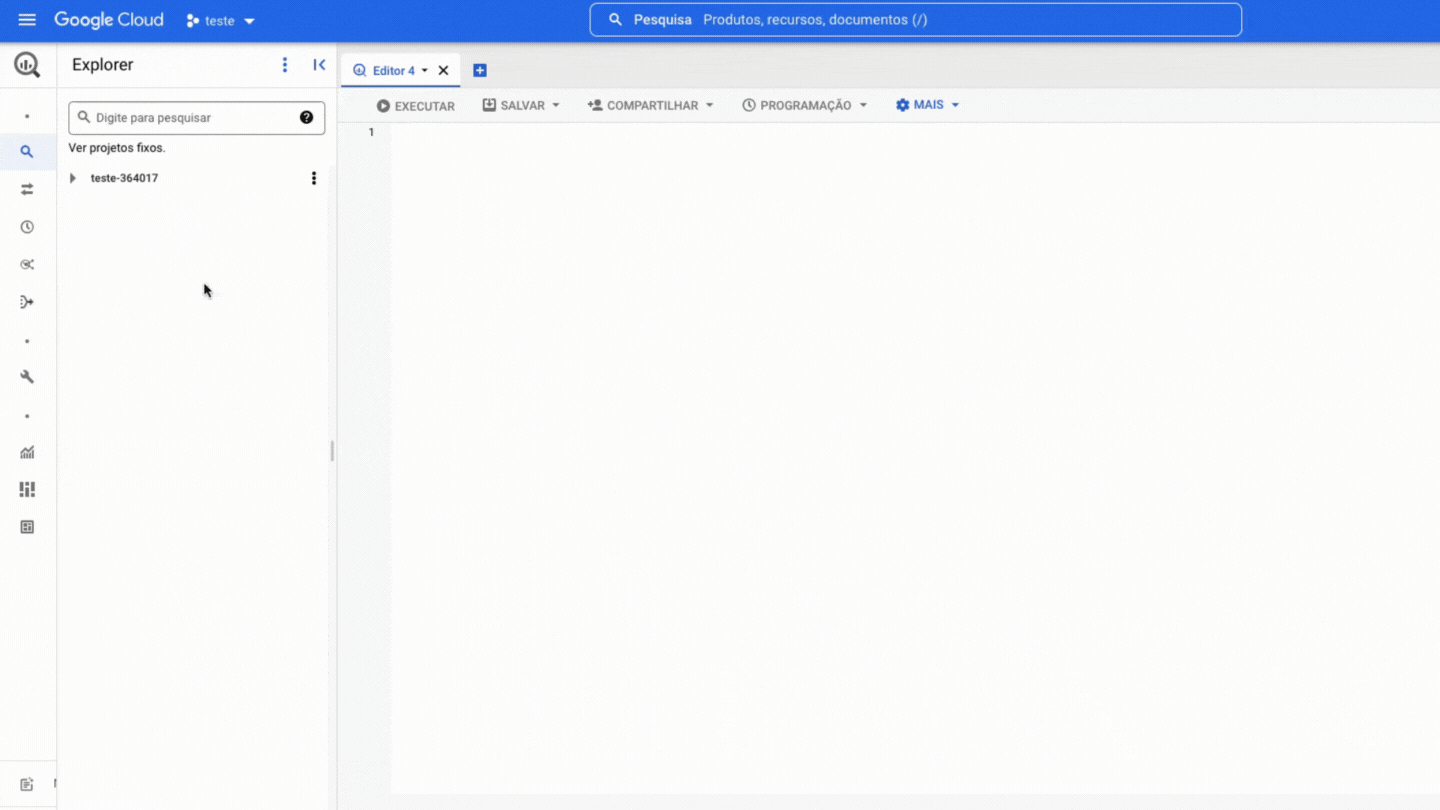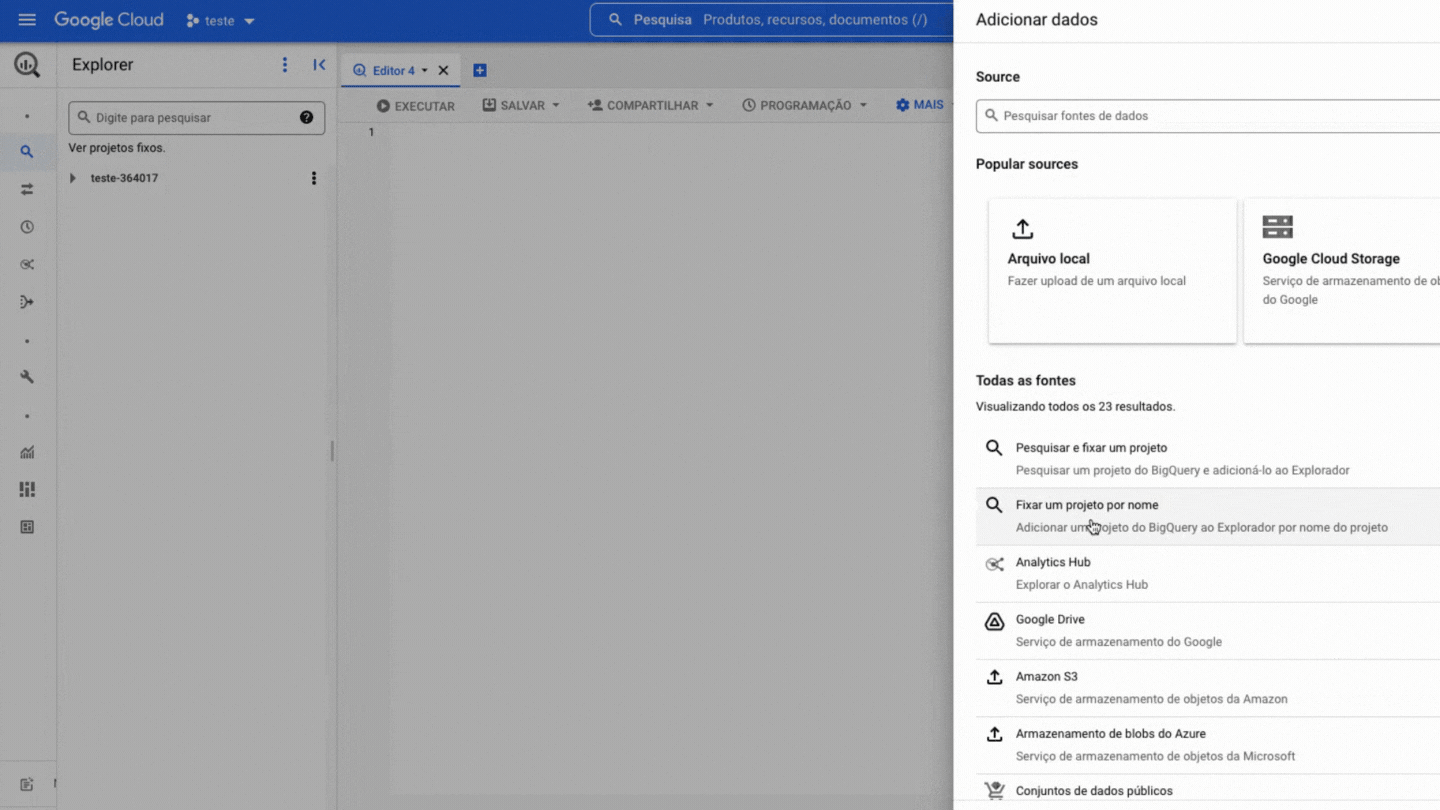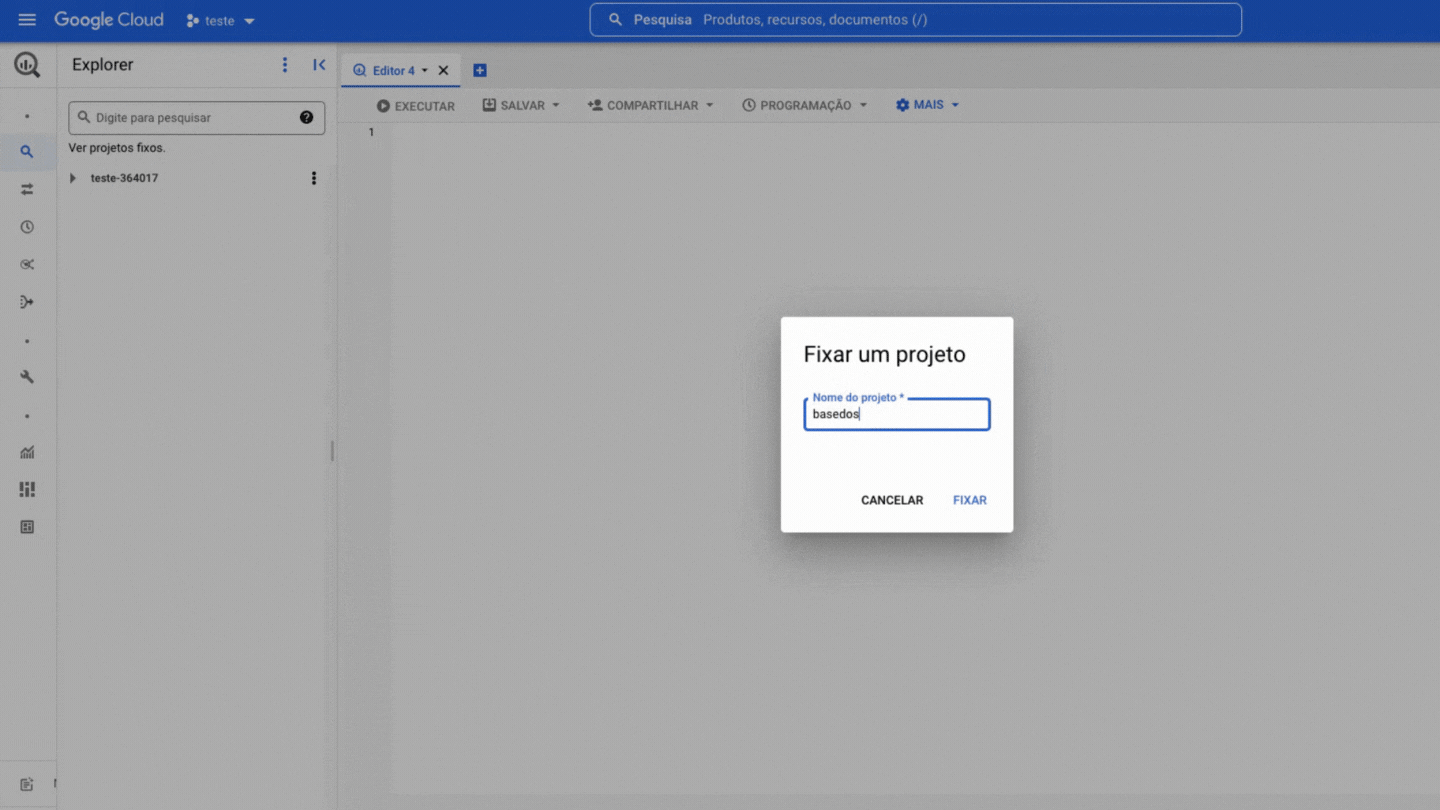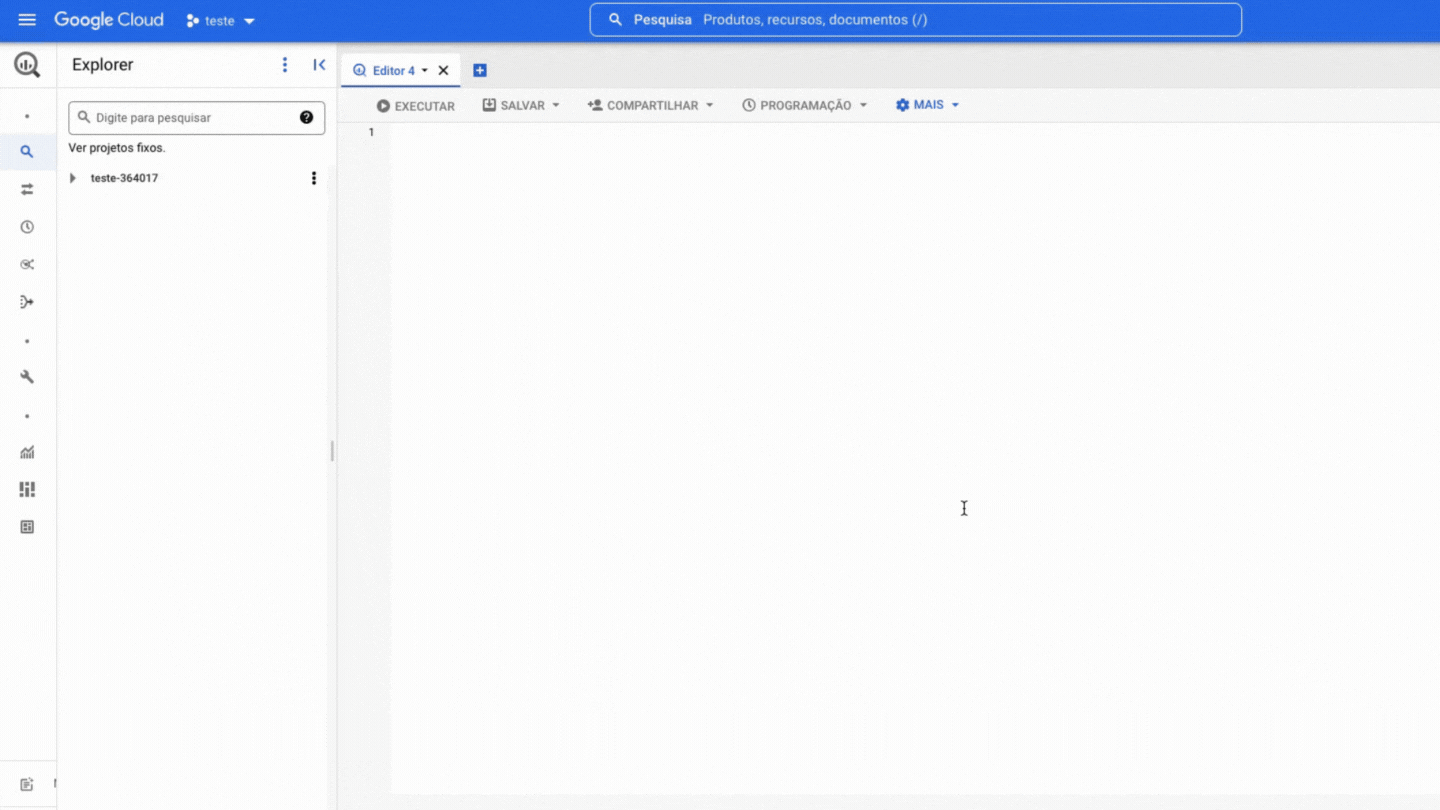
Within the project there are two levels of data organization, datasets and tables, where:
- All tables are organized within datasets, which represent their organization/theme (e.g., the dataset
br_ibge_populacaocontains amunicipiotable with the historical population series at municipal level) - Each table belongs to a single dataset (e.g., the
municipiotable inbr_ibge_populacaois different frommunicipioinbr_bd_diretorios)
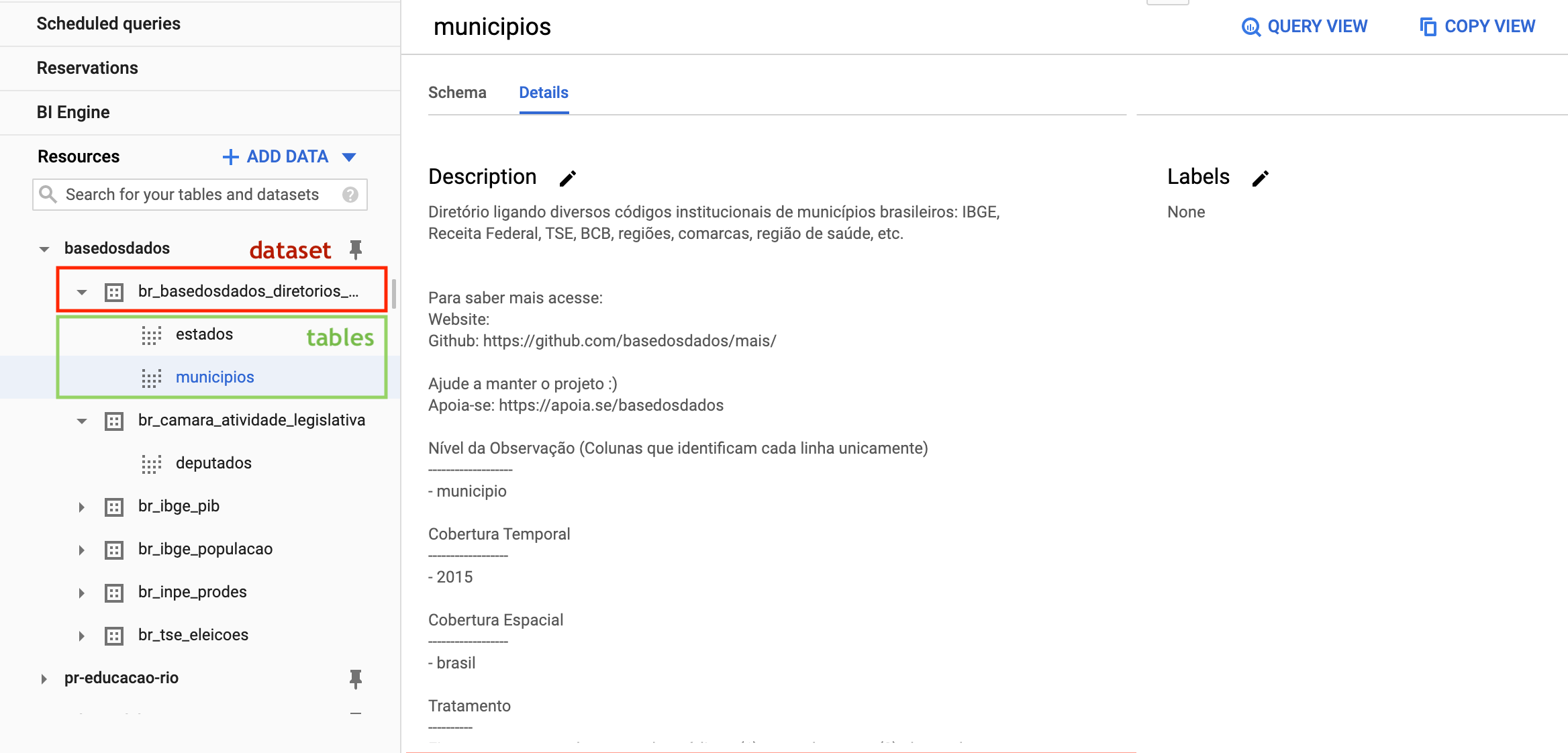
If tables don't appear the first time you access, refresh the page.
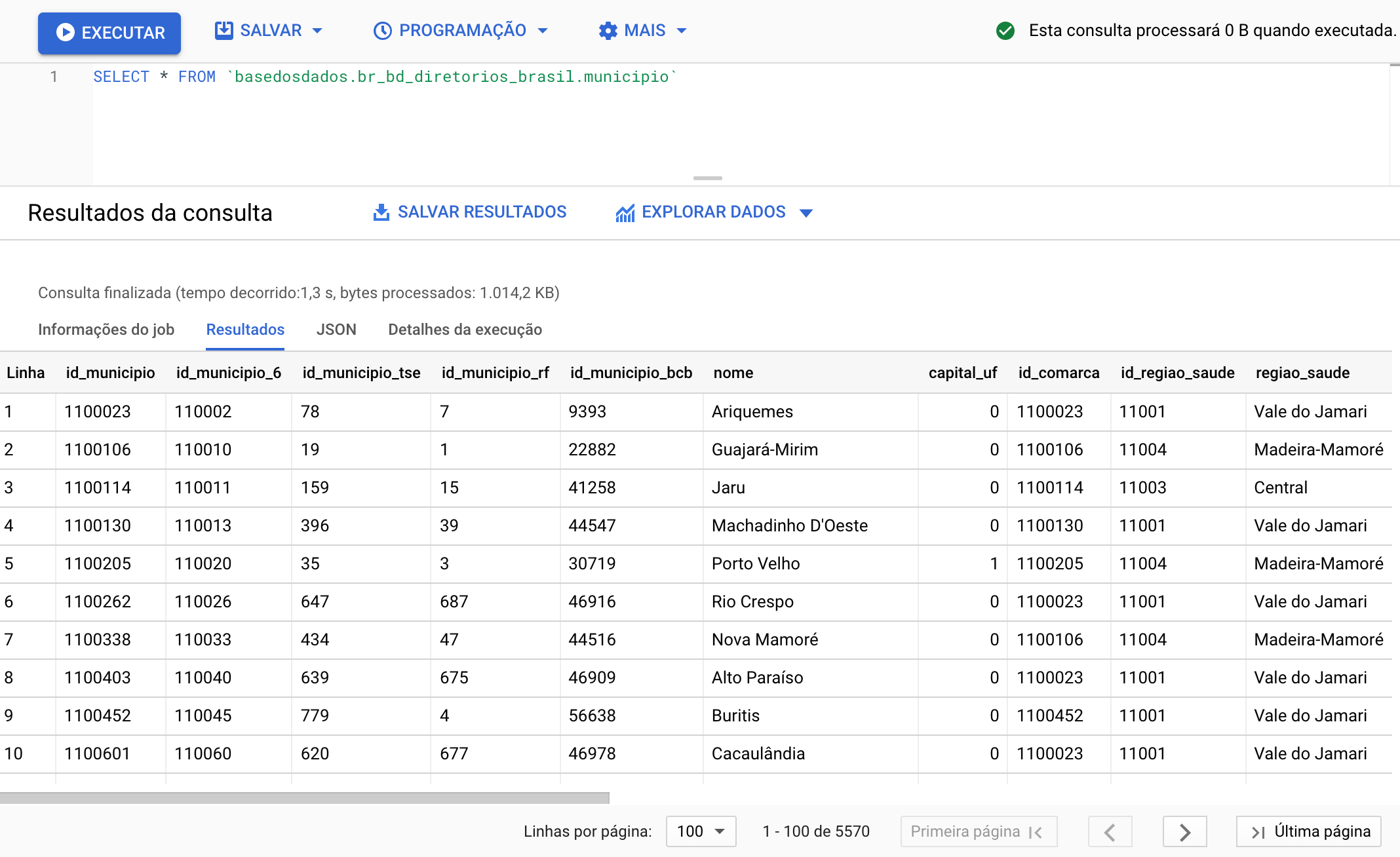
Make your first query!
How about making a simple query? Let's use the BigQuery Query Editor to see information about municipalities directly in our Brazilian directories database. To do this, copy and paste the code below:
SELECT * FROM `basedosdados.br_bd_diretorios_brasil.municipio`
Just click Run and you're done!
Tip
By clicking the 🔍 Query Table button, BigQuery automatically creates
the basic structure of your query in the Query Editor - you just need to complete it with the fields and filters you find necessary.
Understanding BigQuery's Free Usage
This section is dedicated to presenting tips on how to reduce processing costs to maximize the data from BD!
For users who access data in public projects like the BD, the only type of cost associated is the cost of processing queries. The good news, as mentioned above, is that every user gets 1 TB free per month for querying data. If you still don't have a project in BQ, consult the section above to create one.
- Knowing the basics of the BQ interface is important for understanding the article. If you don't have familiariadade or want to revisit the interface, we recommend 3 tracks:
- Our guide using the RAIS - Annual Relation of Information Society tables
- Our collection of videos on YouTube
- The introduction to the interface done by Google
See how to maximize the benefits of free queries
In this section, we present some simple tips to reduce the costs of queries in Big Query and maximize the data from BD! Before moving on to the examples, we'll introduce the basic mechanism for predicting query processing costs in Big Query (BQ).
Cost estimates
In the upper right corner of the BQ interface, there's a notice with an estimate of the processing cost that will be charged to your project after the query execution.
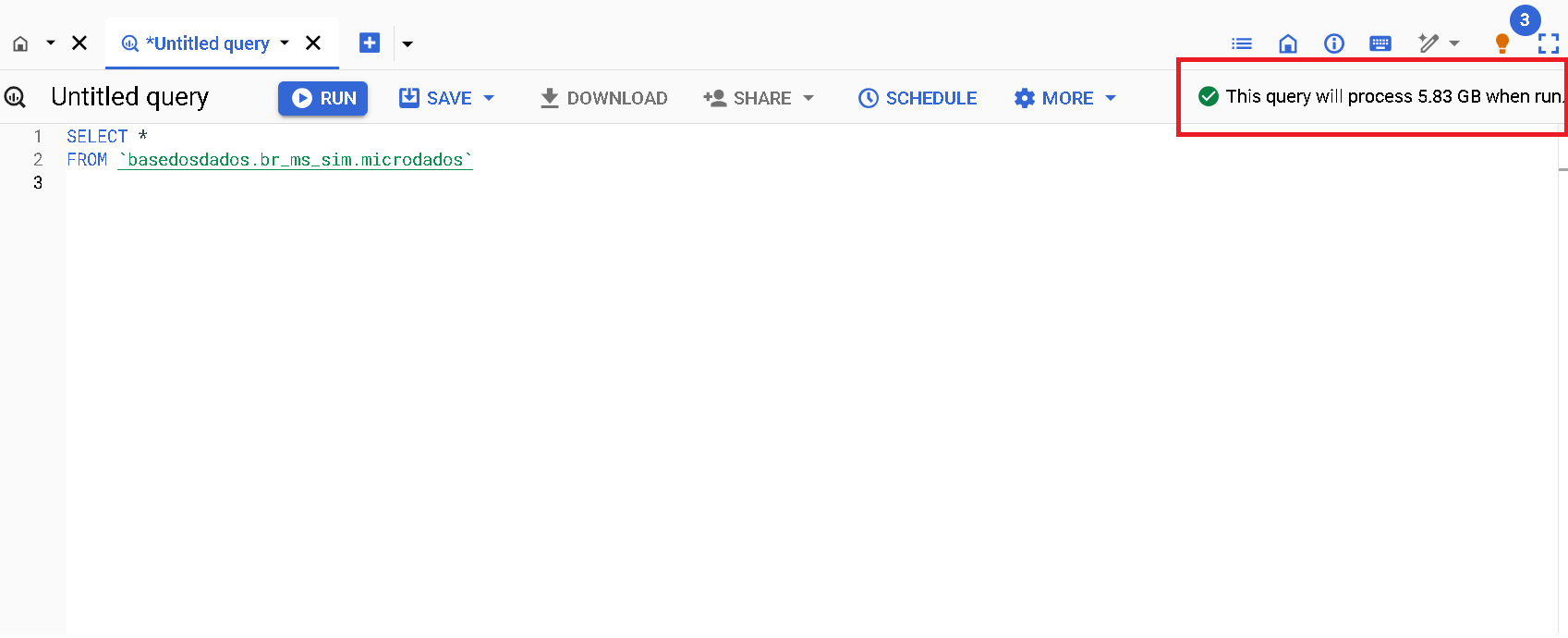
-
This is the basic and readily accessible mechanism for predictability of processing costs. Unfortunately, it doesn't work for all tables. Due to limitations within Big Query itself, queries to specific tables don't display cost estimates. This is the case of tables with Row Access Policy. This means that the number of accessible rows is limited depending on the user. This is the case of tables that are part of the BD Pro service
-
Example of the
agenciatable from thebr_bcb_estbandataset.
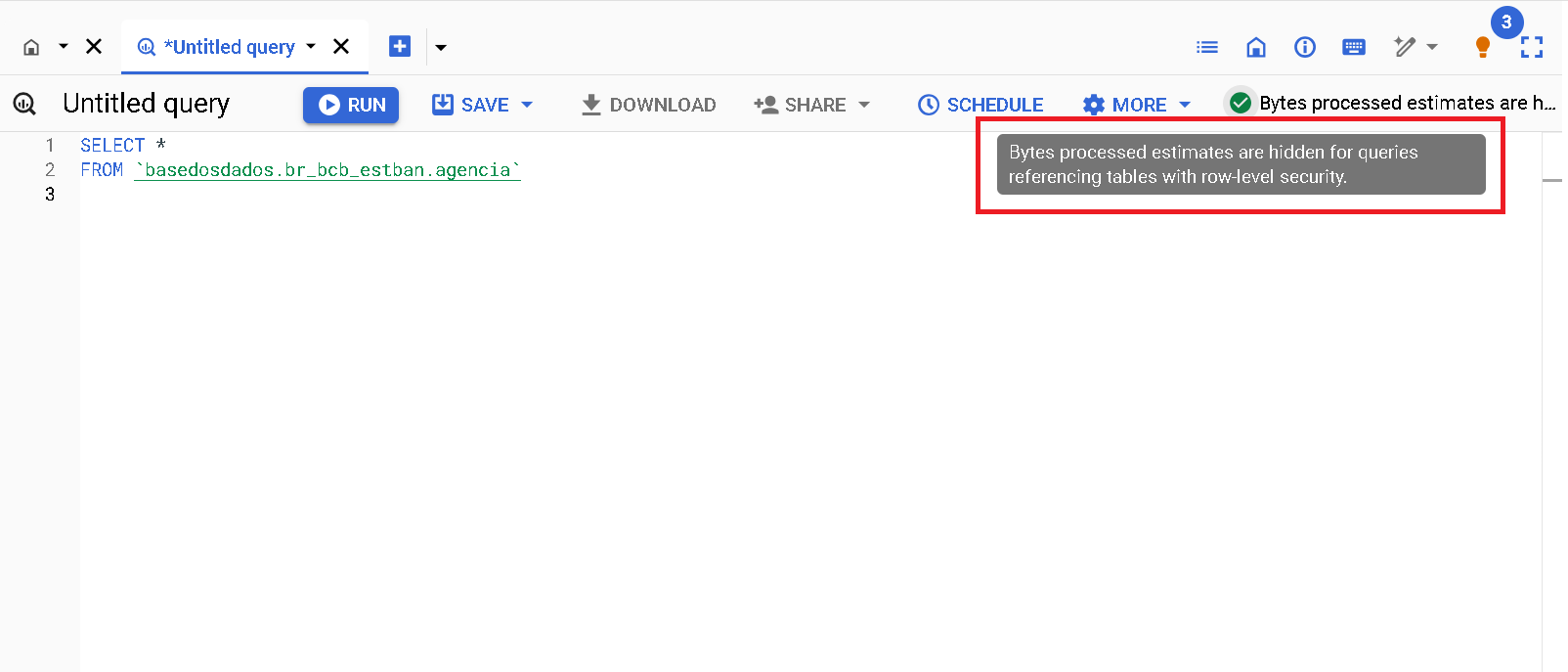 { width=100% }
{ width=100% }
TIP 1: Select only the columns of interest
-
The Big Query architecture uses column-oriented storage, meaning that each column is stored separately. This characteristic has a clear implication regarding processing costs: the more columns are selected, the higher the cost.
-
Avoid: Selecting too many columns
SELECT *
- Recommended practice: select only the columns of interest to reduce the final cost of the query.
SELECT coluna1, coluna2
microdados from the br_ms_sim set.
- Without column selection: estimated cost 5.83 GB
- Selecting 3 columns: estimated cost 0.531 GB (531 MB)
SELECT sequencial_obito, tipo_obito, data_obito FROM `basedosdados.br_ms_sim.microdados`
- To understand the columnar architecture in depth, consult the official Big Query documentation
TIP 2: Use partitioned and clustered columns to filter data
-
Partitions are divisions made in a table to facilitate data management and query. During query execution, Big Query ignores rows that have a partition value different from the one used in the filter. This usually significantly reduces the number of rows read and, what we're interested in, reduces the processing cost.
-
Clusters are organized groups in a table based on the values of one or more specified columns. During query execution, Big Query optimizes data reading, accessing only the segments that contain the relevant values of the cluster columns. This means that instead of scanning the entire table, only the necessary parts are read, which generally reduces the amount of processed data and, consequently, reduces the processing cost.
-
How to know which column was used to partition and cluster a specific table?
-
By the metadata on the table page on the BD website

-
Note that the Partitions in Big Query lists both partitions and clusters.
-
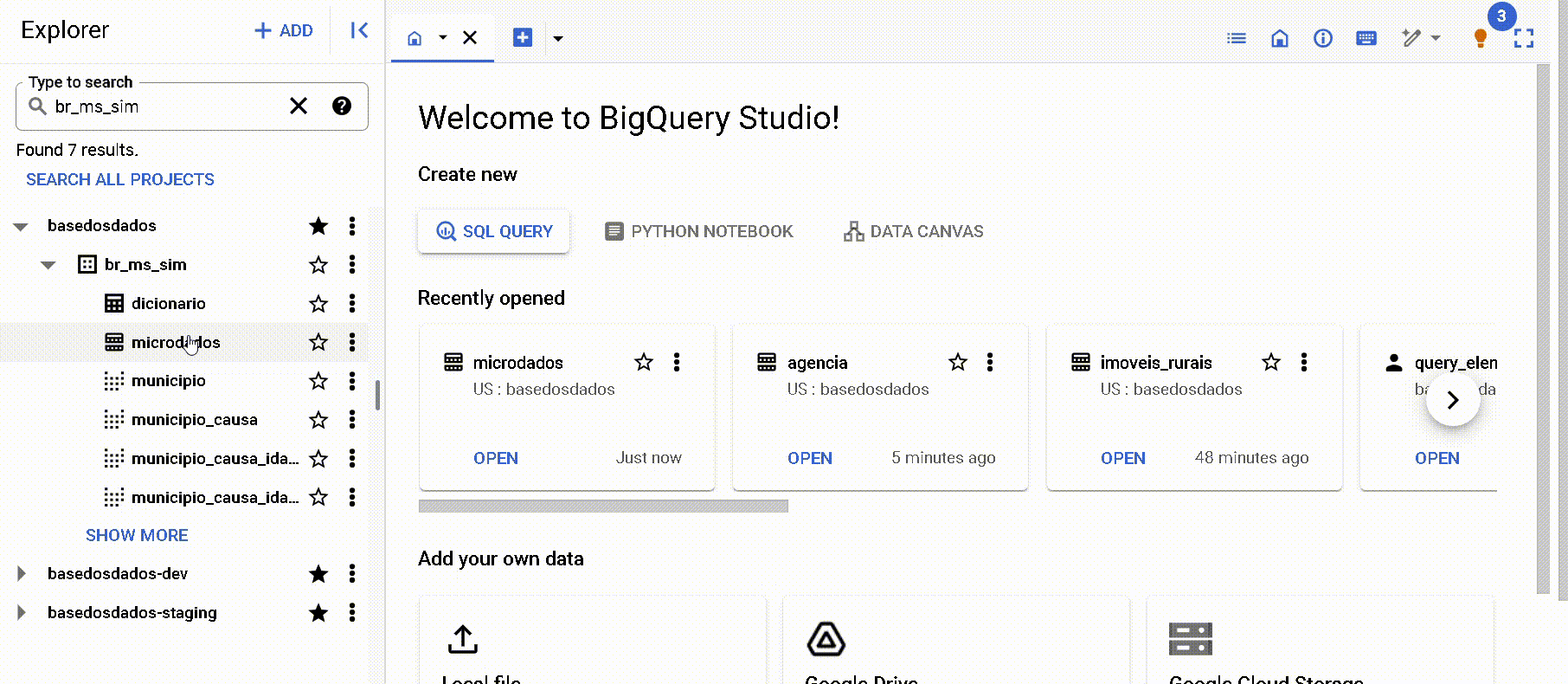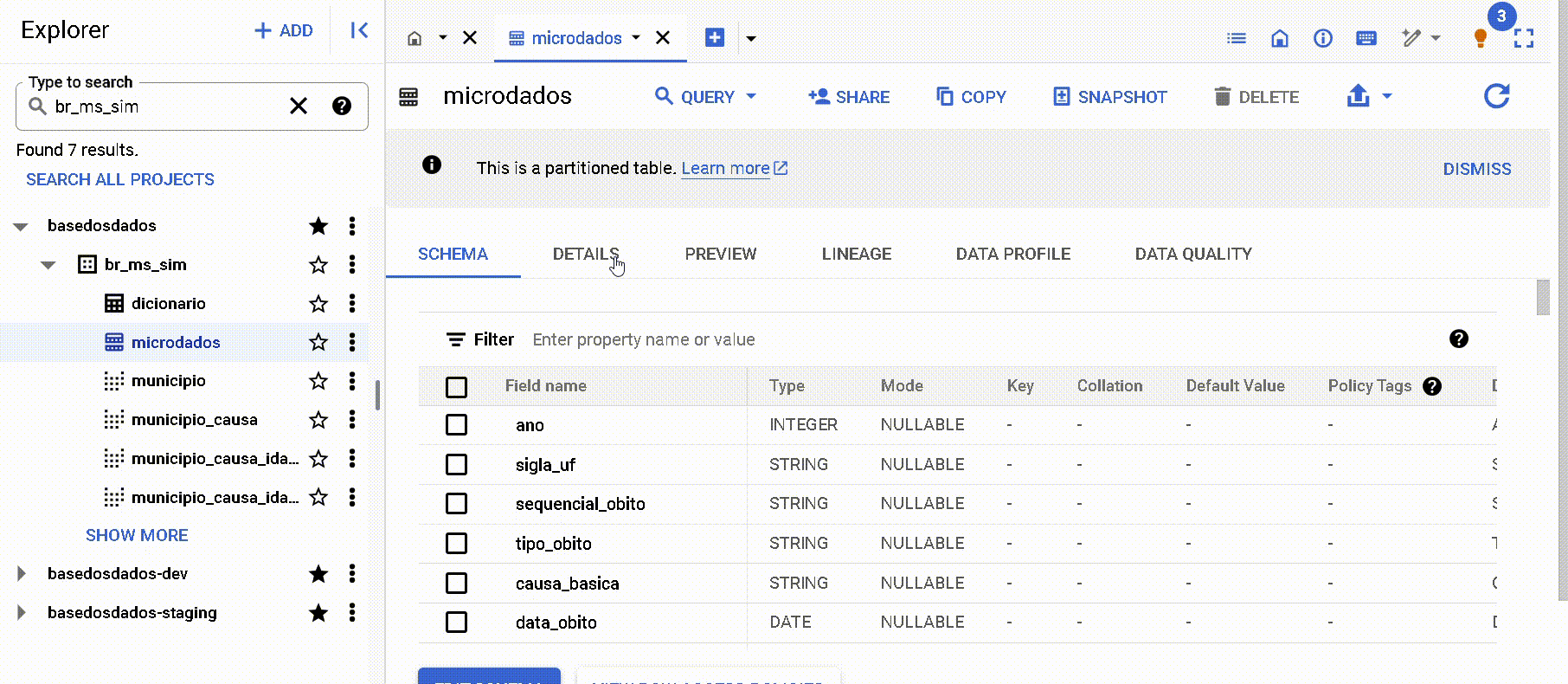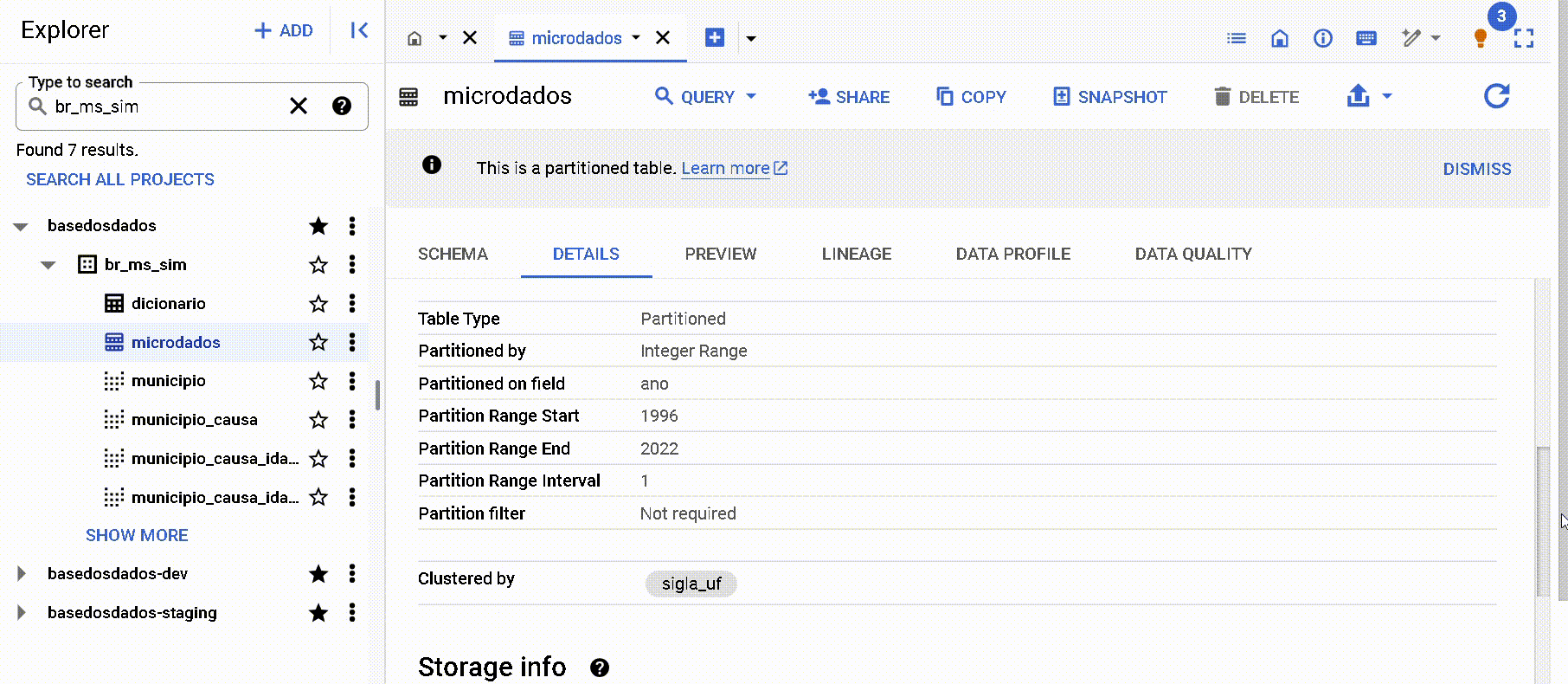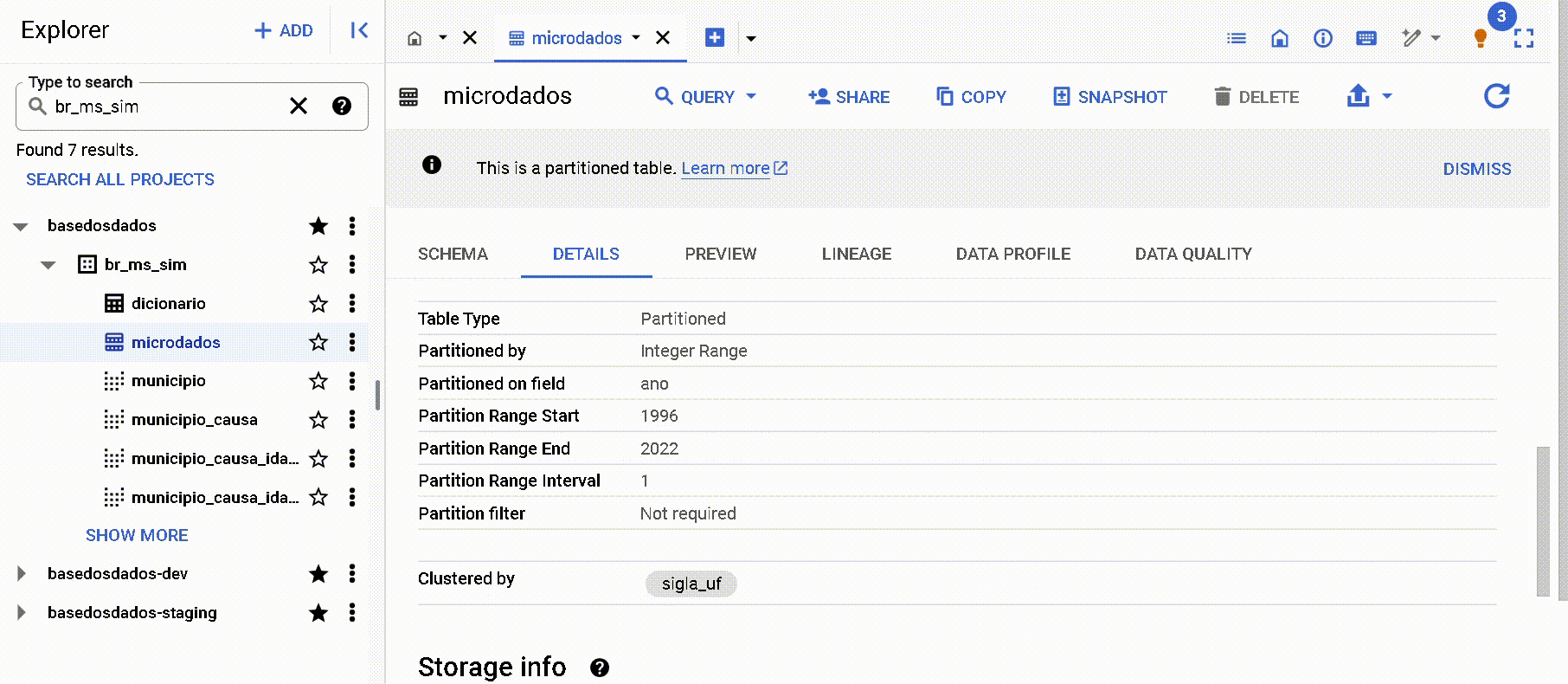
By the metadata on the 'Details' page in Big Query
-
Note that both partitions and clusters are listed. In this case, the column ano was defined as a partition and the column sigla_uf as a cluster.
-
Recommended practice: always try to use partitioned and clustered columns to filter/aggregate data.
-
Example
- Query used with a partitioned column as a filter:
SELECT sequencial_obito, tipo_obito, data_obito FROM `basedosdados.br_ms_sim.microdados` where ano = 2015 - estimated cost: 31.32 MB. The combination of column selection techniques and filtering using partition reduced the estimated cost from the initial query of 5.83 GB to only 31.32 MB
TIP 3: Pay close attention when performing joins between tables
-
Evaluate the real need for JOIN
- Make sure the join is really necessary for the analysis you're performing. Sometimes, alternative operations like subqueries or aggregations can be more efficient.
-
Understand the JOIN logic
- Different types of joins (INNER, LEFT, RIGHT, FULL) have different implications for performance and result. Taking a moment to understand the best option for your analysis goal can help you have more efficient cost control.
- One of the most common problems is the multiplication of unwanted rows in the final result.
- To understand the full picture of good practices and common issues with joins, we recommend the guides SQL Joins in Practice and Maximizing Efficiency with JOIN in SQL Queries to Combine Tables
-
Use the tips above
- Select only the columns of interest
- Use the partitioned columns to filter the data
- Pay attention to cost estimates before executing the query
Tutorials
How to navigate BigQuery
To understand more about the BigQuery interface and how to explore the data, we prepared a complete text in the blog with an example of searching for data from the RAIS - Ministry of Economy.
Tired of reading? We also have a complete video on our YouTube.
Understand the data
BigQuery has a search mechanism that allows you to search by datasets (sets), tables (tables), or labels (groups). We created simple naming rules and practices to facilitate your search - see more.
Understand the use of BigQuery (BQ) for free
Connecting with PowerBI
Power BI is one of the most popular technologies for developing dashboards with relational data. That's why we prepared a tutorial for you to discover how to use the datalake data in the development of your dashboards.
SQL Manuals and Courses
We're starting to learn about SQL to make our queries? Below we provide some recommendations used by our team both in learning and in everyday life: