DB Infrastructure
Our infrastructure team ensures that all packages and pipelines are working optimally for the public. We use Github to manage all code and keep it organized, where you can find issues for new features, bugs, and improvements we're working on.
How our infrastructure works
Our infrastructure consists of 3 main fronts:
- Data ingestion system: from upload to production deployment;
- Access packages
- Website: Front-end, Back-end, and APIs.
Currently, it's possible to collaborate on all fronts, with emphasis on developing checks and balances and website updates.
We suggest joining our Discord channel to ask questions and interact with other contributors! :)
Data ingestion system
The system has development (basedosdados-dev), staging (basedosdados-staging), and production (basedosdados) environments in BigQuery. The data upload processes are detailed in the image below, with some of them being automated via Github Actions.
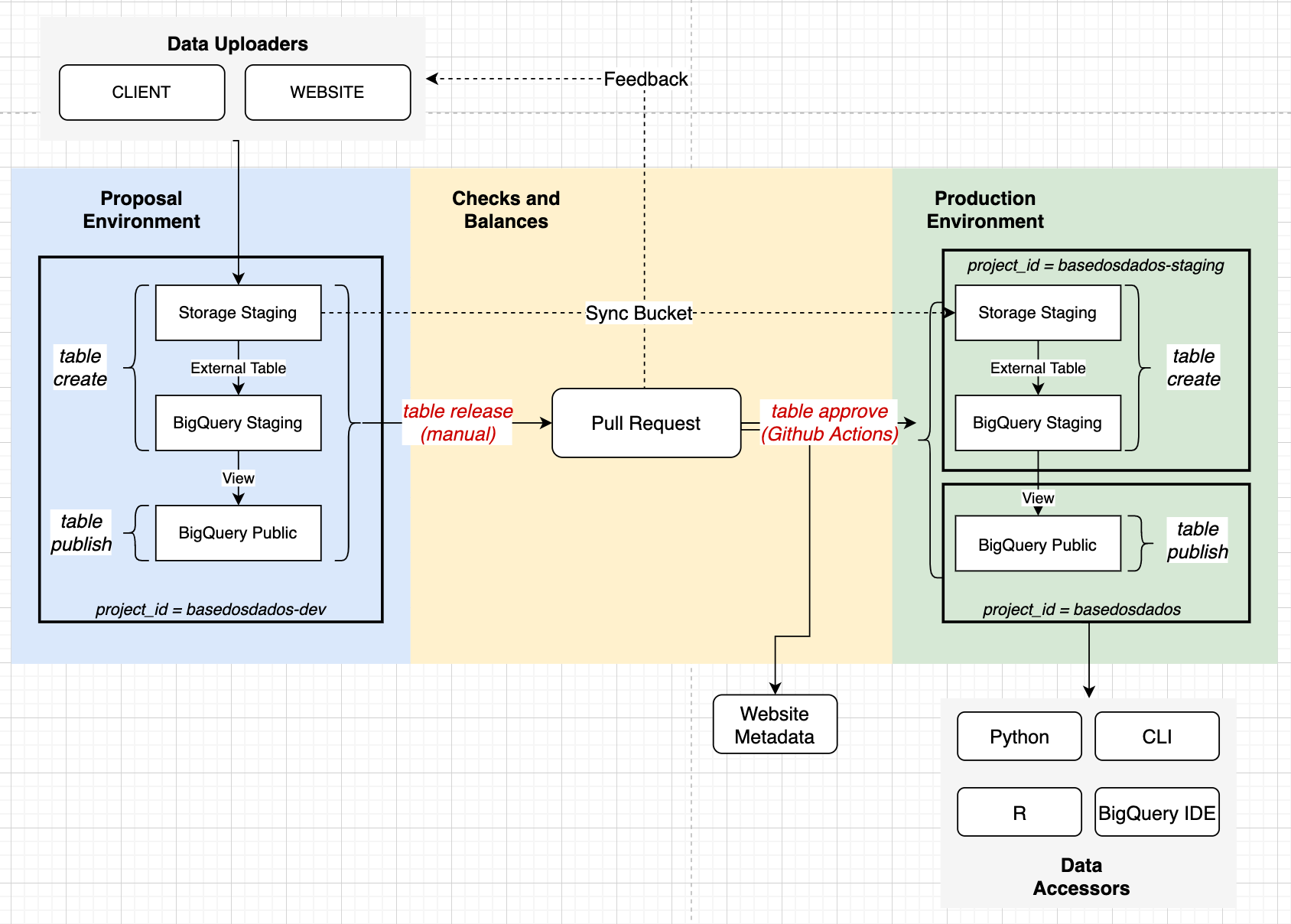
We explain the system's operation in more detail on our blog.
How to contribute?
- Improving system documentation here :)
- Creating automatic data and metadata quality checks (in Python)
- Creating new issues and improvement suggestions
Access packages
The datalake access packages are constantly being improved, and you can collaborate with us on new features, bug fixes, and much more.
How to contribute?
Website
Our website is developed in Next.js and consumes a CKAN metadata API. The site's code is also on our Github.