Infraestructura de BD
Nuestro equipo de infraestructura se asegura de que todos los paquetes y pipelines funcionen de la mejor manera para el público. Utilizamos Github para gestionar todo el código y mantenerlo organizado, donde puedes encontrar issues de nuevas funcionalidades, errores y mejoras en las que estamos trabajando.
Cómo funciona nuestra infraestructura
Nuestra infraestructura se compone de 3 frentes principales:
- Sistema de ingestión de datos: desde la carga hasta la disponibilización en producción;
- Paquetes de acceso
- Sitio web: Front-end, Back-end y APIs.
Actualmente es posible colaborar en todos los frentes, con énfasis en el desarrollo de los pesos y contrapesos y la actualización del sitio.
¡Sugerimos que te unas a nuestro canal de Discord para resolver dudas e interactuar con otros(as) colaboradores(as)! :)
Sistema de ingestión de datos
El sistema tiene ambientes de desarrollo
(basedosdados-dev), homologación (basedosdados-staging) y producción
(basedosdados) en BigQuery. Los procesos para la subida de datos están
detallados en la imagen de abajo, siendo algunos de ellos automatizados
vía Github Actions.
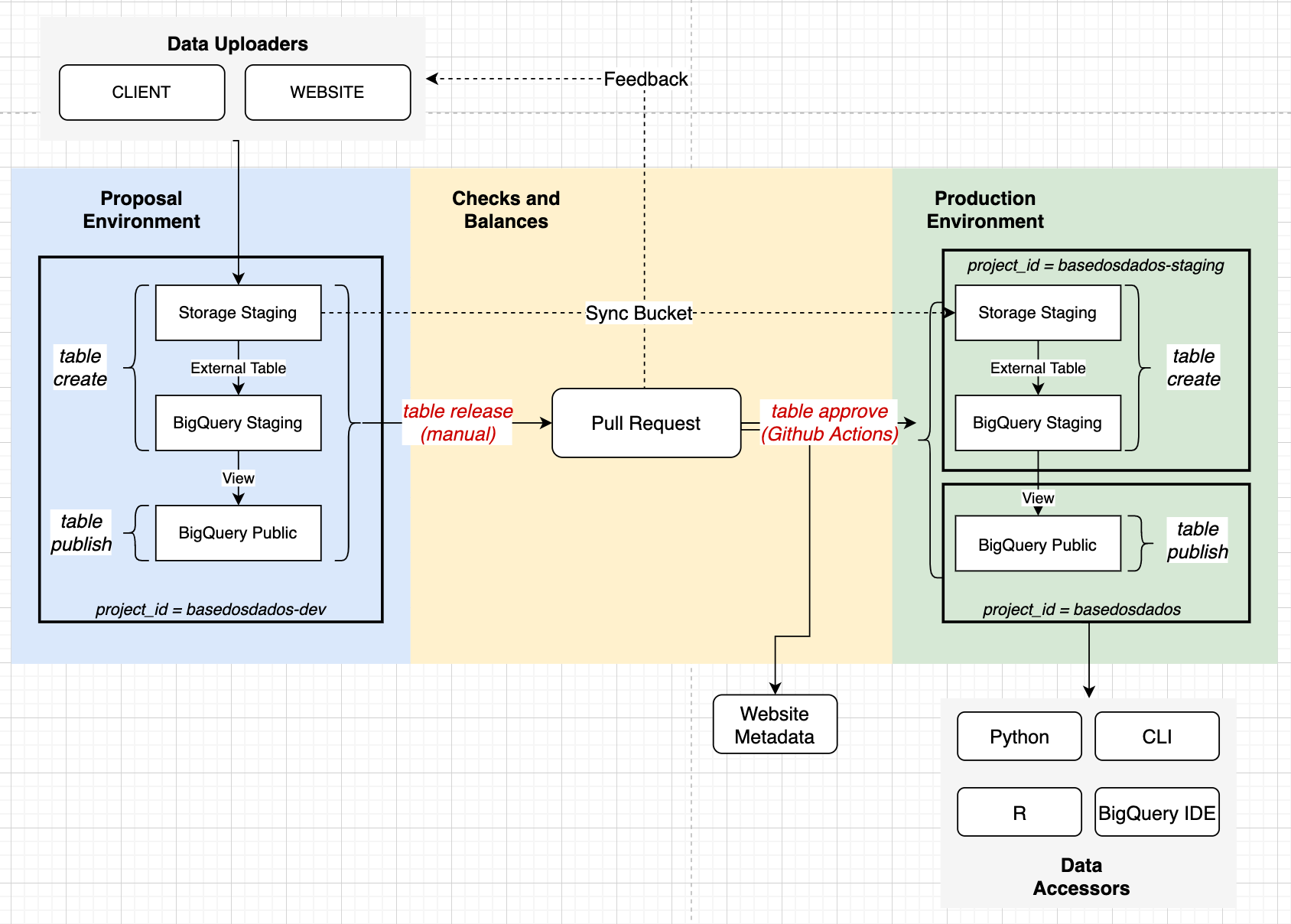
Explicamos con más detalles el funcionamiento de este sistema en el blog.
¿Cómo contribuir?
- Mejorando la documentación del sistema aquí :)
- Creando verificaciones automáticas de calidad de datos y metadatos (en Python)
- Creando nuevos issues y sugerencias de mejoras
Paquetes de acceso
Los paquetes de acceso al datalake están en constante mejora y puedes colaborar con nosotros con nuevas funcionalidades, corrección de errores y mucho más.
¿Cómo contribuir?
- Explora los issues del paquete Python
- Explora los issues del paquete R
- Ayuda a desarrollar el paquete en Stata
Sitio web
Nuestro sitio web está desarrollado en Next.js y consume una API de metadatos de CKAN. El código del sitio también está en nuestro Github.